Data Quality
Wouter Beek (w.g.j.beek@vu.nl)

Part I: What is the problem>?
After 15 years semantic data cannot be…
- found
- read
- queried
- reasoned over
Many PhD students' worse nightmare.
Problem 1: Most data cannot be found
SotA findability comparable to 1995 Yahoo! index

Problem 2: Most data cannot be read
E.g., Freebase <10% syntactically correct.
Current approaches are inherently slow: standards, guidelines, best practices, tools, education.
This takes decades!
Why is data dirty?
- Character encoding issues
- Socket errors
- Protocol errors
- Corrupted archives
- Authentication problems
- Syntax errors
- Wrong metadata
- Lexical form ↛ value
- Non-canonical lexical form
- Logically inconsistent
- …
Problem 3: Most data cannot be queried

- Few SPARQL endpoints with high availability.
- Web-scale ‘Follow Your Nose’ = DoS attack
- SPARQL endpoints with high availability use non-standardized pagination.
- No streaming
- No anytime behavior
Problem 4: Most data cannot be reasoned over
- SPARQL Entailment Regimes are not standardized.
- Some entailment results cannot be expressed in RDF.
- Existing reasoners give incomplete results.
- Web-scale reasoning is only performed in the lab
- Real-world reasoning immediately goes ex falso quodlibet
Part II: How to solve this?
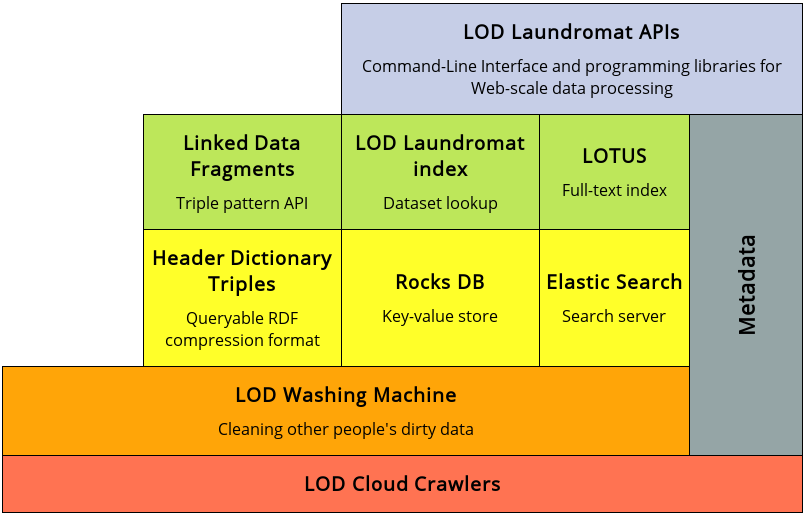
lodlaundromat.org





Beek & Rietveld & Bazoobandi & Wielemaker & Schlobach. 2014. “LOD laundromat: A Uniform Way of Publishing Other People’s Dirty Data” ISWC.
Implementation
- ClioPatria
- Wielemaker & Beek & Hildebrand & Van Ossenbruggen. 2016. ‘ClioPatria: A SWI-Prolog Infrastructure for the Semantic Web’ in Semantic Web Journal (github.com/ClioPatria/ClioPatria).
- SWI-Prolog
- github.com/SWI-Prolog/swipl-devel
- Header Dictionary Triples (HDT)
- Fernández & Martínez-Prieto & Gutiérrez & Polleres & Arias. 2013. ‘Binary RDF representation for publication and exchange(HDT)’ in Web Semantics: Science, Services and Agents on the World Wide Web, Vol. 19, p. 22-41 (rdfhdt.org).
Data access (1/2)

Data access (2/2)

Semantic Web layer cake

Alt. Semantic Web layer cake
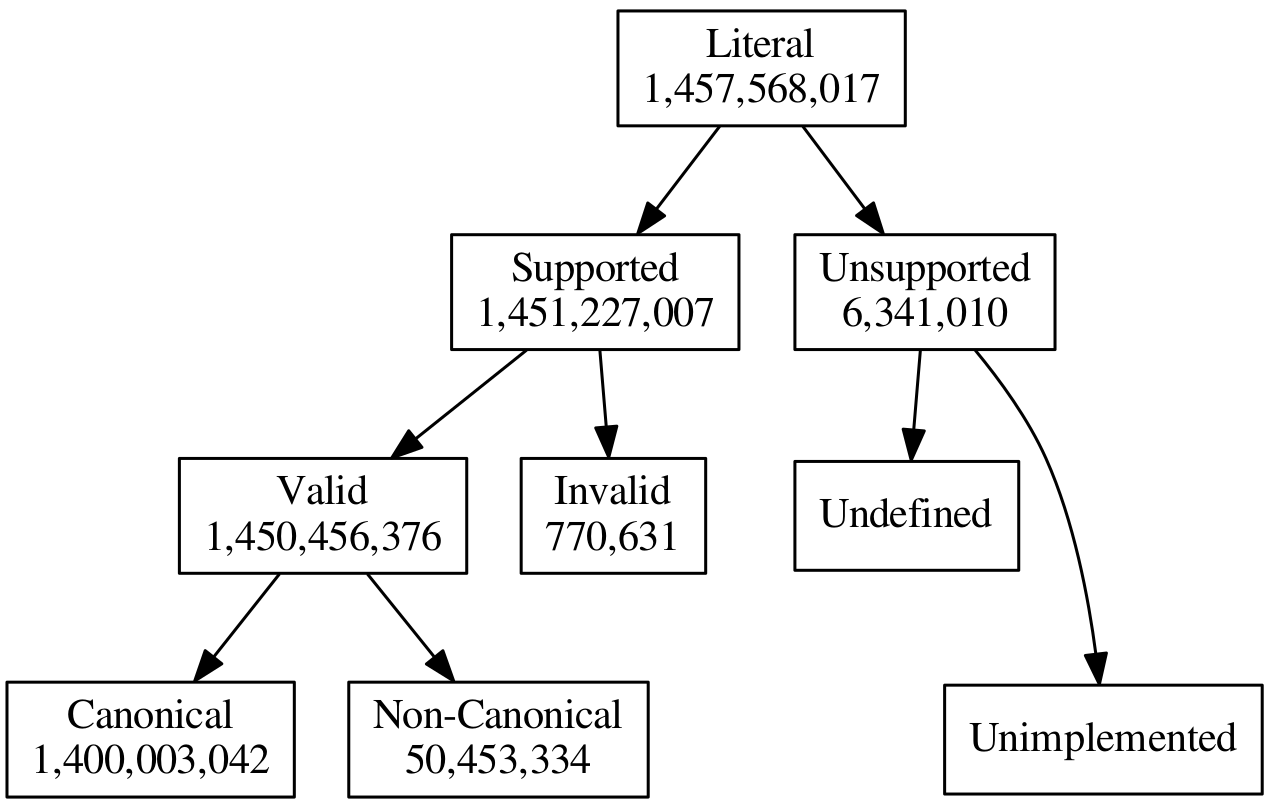
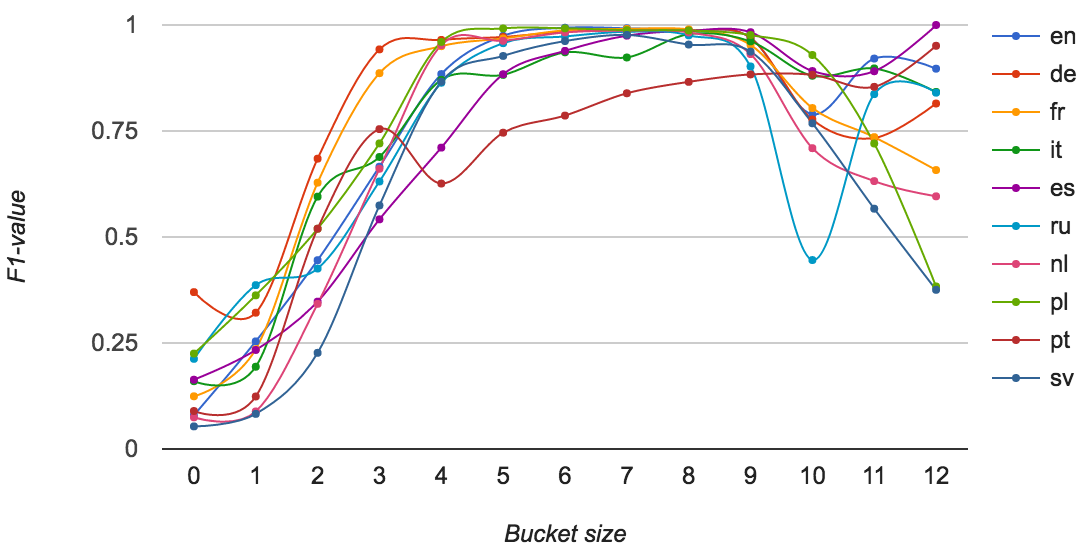
Literally Better: Cleaning literals
Why literals?
- Concise notation for infinite value spaces.
- Encoding of linguistic/text-based content.
W. Beek & F. Ilievski & J. Debattista & S. Schlobach. “Literally Better: Analyzing and Improving the Quality of Literals” (under submission)
Benefits of high-quality literals
- Efficient computation through canonicity
- Data enrichment by improved instance matching
- User eXperience: language preference, “value labeling”
- Improve NLP tasks with background knowledge
Thank you for your attention!
- WWW: wouterbeek.com
- WWW: lodlaundromat.org
- Email: w.g.j.beek@vu.nl
- Twitter:
@WGJBeek