Near Sameness is Somewhat the Same as Sameness
June 11th, 2018
Wouter Beek (w.g.j.beek@vu.nl), Joe Raad (joe.raad@agroparistech.fr), Jan Wielemaker, and Frank van Harmelen

Part I: Motivation
Linked Data requires owl:sameAs
Formal meaning
〈x, owl:sameAs, y〉 means
that (∀P)(Px ↔ Py)
Linked Data
“Include links to other URIs, to discover more
things.”
[4th Linked Data principle]
Linked data requires owl:sameAs
louvre:monaLisa
dc:created "1503"^^xsd:gYear;
dc:creator "Da Vinci".louvre:monaLisa owl:sameAs sothebys:somePainting.sothebys:somePainting
sothebys:auctionDate "2018-06-07"^^xsd:date;
sothebys:price "€1.000,-";
sothebys:contact "mailto:bidding@sothebys.com"^^xsd:anyURI.owl:sameAs we cannot link
our data.
Similarity is not good enough
SKOS exactMatch indicates a high degree of confidence that two concepts can be used interchangeably across a wide range of information retrieval applications.
The only thing worse than owl:sameAs is
‘clever’ replacements for owl:sameAs.
lexvo:nearlySameAs lexvo:somewhatSameAs owl:sameAs.lexvo:nearlySameAs lexvo:nearlySameAs lexvo:somewhatSameAs?owl:sameAs lexvo:somewhatSameAs bbc:sameAs?Use cases
- Findability through backlinks
- Query Answering under OWL entailment
- Ontology Alignment
- Empirical Semantics
We need an enabler for empirical research into
how owl:sameAs is actually being used.
The analytic approach: “people make mistakes” / “it's just noise” is not enough.
| sameas.org | www.sameas.cc | |
|---|---|---|
| № terms | 203M | 180M |
| № statements | 345M | 559M |
| № identity sets | 63M | 49M |
www.sameAs.cc
requirements
- A performant and cost-effective solution for determining whether two things are (claimed to be) the same.
- This solution must scale to the LOD Cloud.
- This solution must be formally
interpretable
(no
skos:exactMatch,rdfs:seeAlso). - It must be calculated incrementally.
Part II: Approach
Formal properties of Identity
Identity is the smallest equivalence relation, it is:
- reflexive (x,x)
- symmetric (x,y) → (y,x)
- transitive (x,y) ∧ (y,z) → (x,z)
Example
Explicit identity relation
(domain {:a,:b,:c,:d})
:a owl:sameAs :b.:d owl:sameAs :b.Corresponding implicit identity relation
:a owl:sameAs :a.
:a owl:sameAs :b.
:a owl:sameAs :d.
:b owl:sameAs :a.
:b owl:sameAs :b.:b owl:sameAs :d.
:c owl:sameAs :c.
:d owl:sameAs :a.
:d owl:sameAs :b.
:d owl:sameAs :d.Obtain the explicit identity relation
http://lod-a-lot.lod.labs.vu.nl
Fernández et al. 2017
Extract the explicit identity relation
prefix owl: <http://www.w3.org/2002/07/owl#>
construct {
?s owl:sameAs ?o
} where {
{
select distinct ?s ?o {
?s owl:sameAs ?o
filter(?s < ?o)
}
}
}Result set size: 558.9M
Create an HDT file in 4 hours (1 CPU core); 4.5GB + 2.2GB index
Compaction
For calculating the implicit identity relation we do not need the full explicit identity relation (558.9M):
- 2.8M
- reflexive triples
- 225M
- duplicate symmetric triples
Compaction reduces size by 42% (311M triples).
Calculate the implicit identity relation
- RDF nodes : N
- key : ID ↦ Ƥ(N)
- val : N ↦ ID
- Identity closure for x : key(val(x))
Add an explicit identity pair (x,y)
- X and y are new
- x ↦ id, y ↦ id, id ↦ {x,y}
- Only x is new (only y is new)
- x ↦ val(y), val(y) ↦ key(val(y)) ∪ {x}
- x and y are old
- val(x) ↦ key(val(x)) ∪ key(val(y)), ∀ y'∈key(val(y)) . y' ↦ val(x)
Run time: 5 hours (2 CPU cores); 9.3GB disk (RocksDB)
Part III: Analysis
Terms in the explicit identity relation
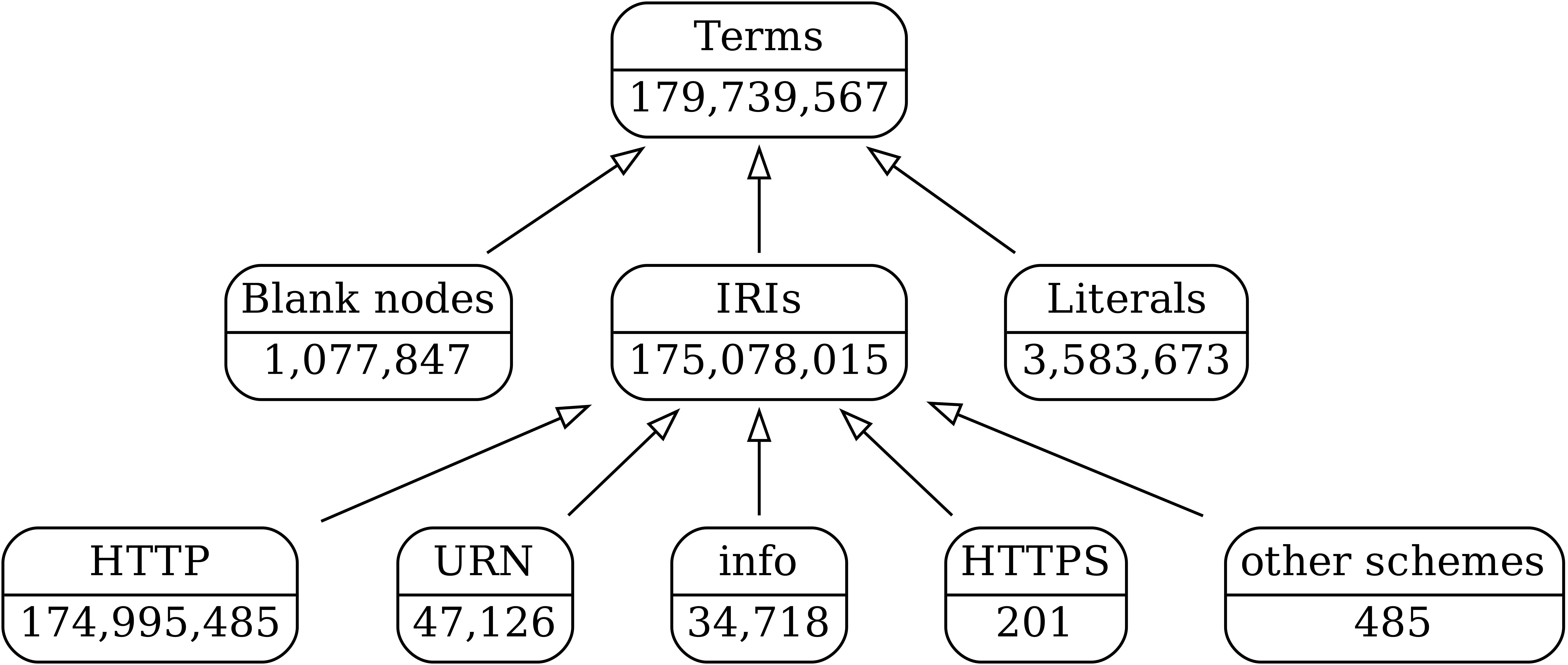
Explicit identity statements per term
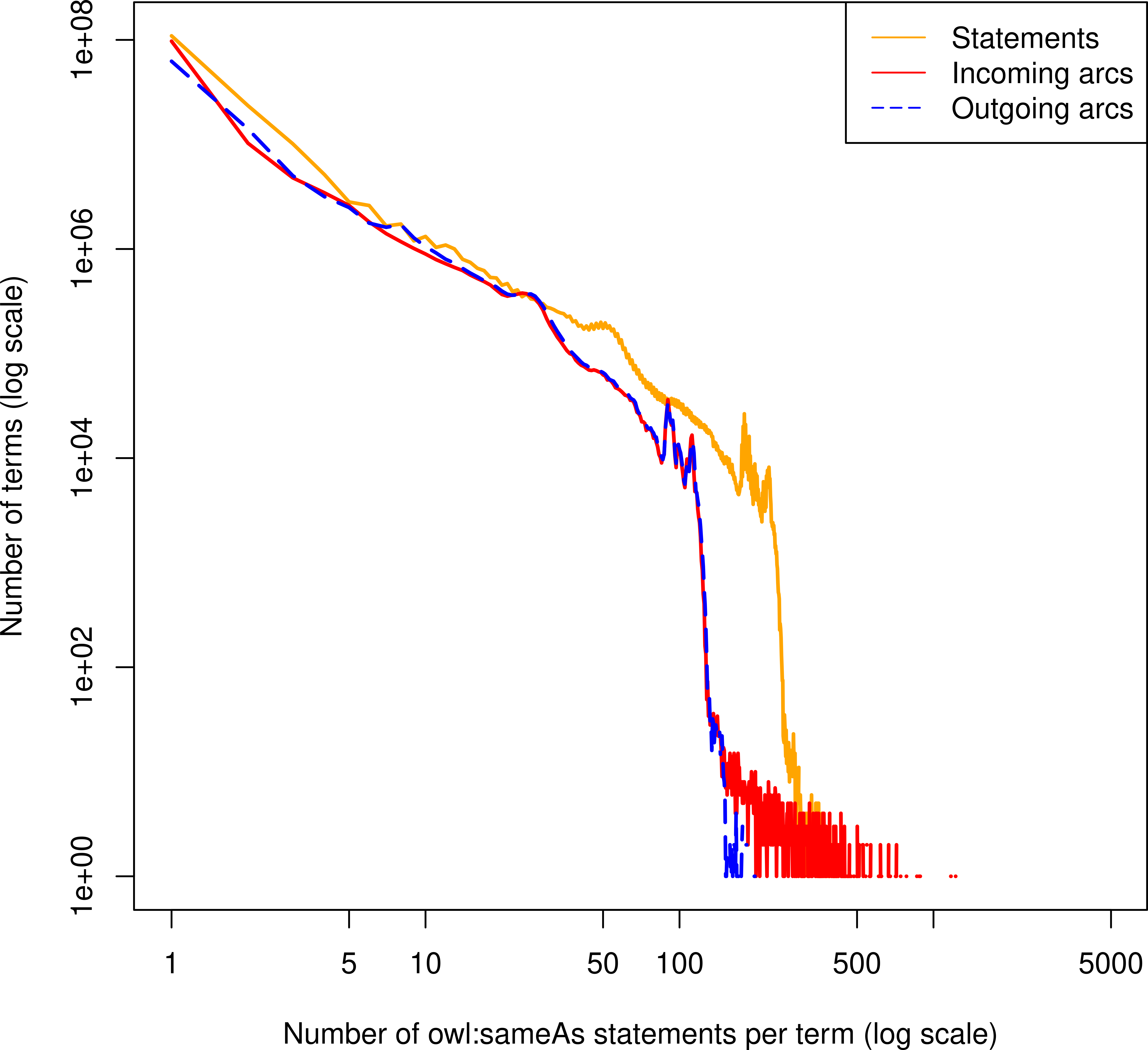
Aggregation by namespace
Relatively few namespaces have internal links. (Indicator that datasets enforce UNA internally.)
Domain-specific identity hubs:
- Bibliographic datasets
www.bibsonomy.org- Geographic datasets
geonames.org- Biochemistry datasets
bio2rdf.org- Online reviews
revyu.com
Terms in implicit identity relation

- № IRIs
- 3,543,226,266
- Most popular IRI
rdf:type(639,478 documents, 3,321,354,308 triples)- Plateau between IRI 100 & 10K
- European Environment Information and Observation Network (Eionet)
- № IRIs in 1 dataset
- 2,981,438,990 IRIs (84%)
№ Identity sets in implicit identity relation
- Singleton identity sets
- 5,044,948,869
- Non-singleton identity sets
- 48,999,184
Non-singleton identity sets

31,3.8,556 identity sets (63.96%) have cardinality 2.
The largest identity set has cardinality 177,794. It includes Albert Einstein, the countries of the world, and the empty string. Responsible for 31,610,706,436 (90%) of the implicit identity relation.
Kernel calculation
The size of a minimal explicit identity relation that denotes the same implicit identity relation.
- Runtime
- 55.6 seconds (3 CPU cores)
- Kernel size
- 130,673,158 triples
- Percentage of the implicit identity relation
- 0.37%
- Percentage of the explicit identity relation
- 23.4%
Part IV: Practical example
Explicit identity statements for ‘Barack Obama’
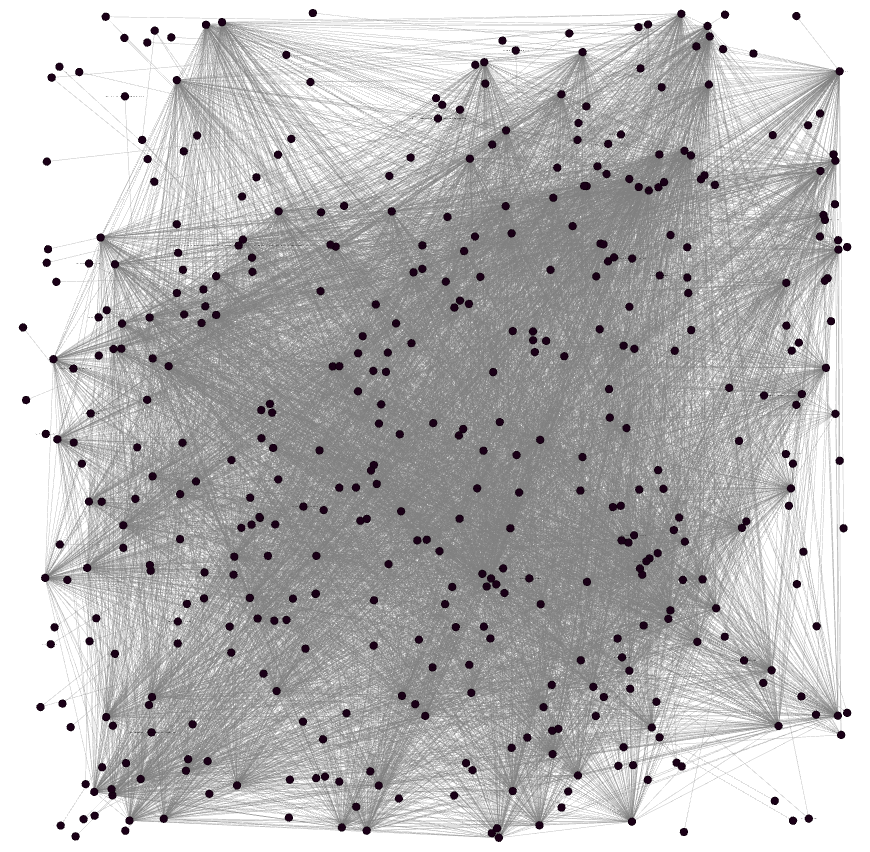
But are these really the same resource?
http://als.dbpedia.org/resource/Barack_Obama
http://am.dbpedia.org/resource/ባራክ_ኦባማ
http://data.nytimes.com/obama_barack_per
http://viaf.org/viaf/52010985
http://yago-knowledge.org/resource/Barack_Obama
http://rdf.freebase.com/ns/m.02mjmrhttp://dbpedia.org/resource/Administration_of_Barack_Obama
http://dbpedia.org/resource/Barack_Obama_Cabinet
http://dbpedia.org/resource/Barack_Obama_presidency
http://yago-knowledge.org/resource/Presidency_of_Barack_Obama
http://rdf.freebase.com/ns/m.05b6w1g‘Barack Obama’ after community detection

Communities correspond to roles:
- person
- senator
- president
- government
Future work
- Close IRIs under syntactic equivalence
- Close IRIs under protocol equivalence
http://dbpedia.org/resource/Cretehttps://dbpedia.org/resource/Crete
- New LOD Laundromat scrape & LOD-a-lot file
- Empirical Semantics:
- study how meaning is used in practice (example).
Thank you for your attention!

- WWW: https://www.sameAs.cc
- WWW: wouterbeek.com
- Email: w.g.j.beek@vu.nl
- Email: joe.raad@agroparistech.fr