The ‘K’ in ‘Semantic Web’ Stands for ‘Knowledge’
19th June 2018
Wouter Beek (w.g.j.beek@vu.nl)
Simplifying assumptions of KR research
[1/6] Quantity Assumption
“There is only little data”





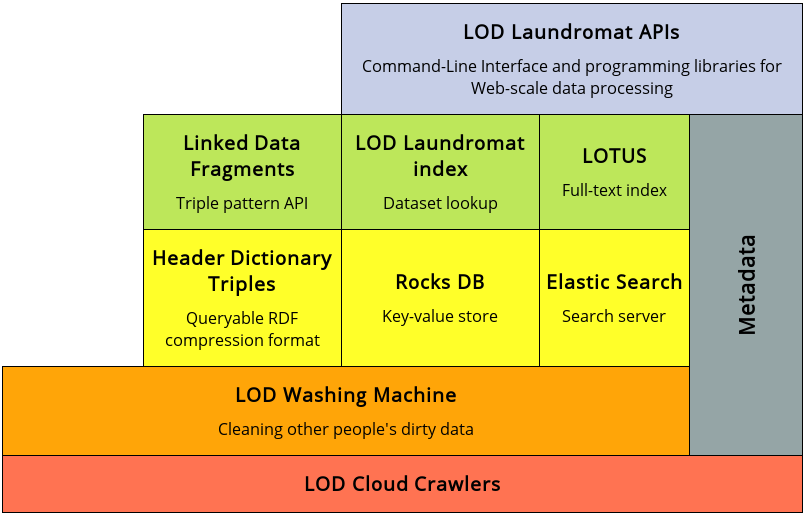
See Chapter 2: Scaling Data Cleaning to the Web
[2/6] Quality Assumption
“Statements are well-defined and interpretable”

See Chapter 4: Scaling Data Quality to the Web
[3/6] Accessibility Assumption
“Data can be easily (re)used”
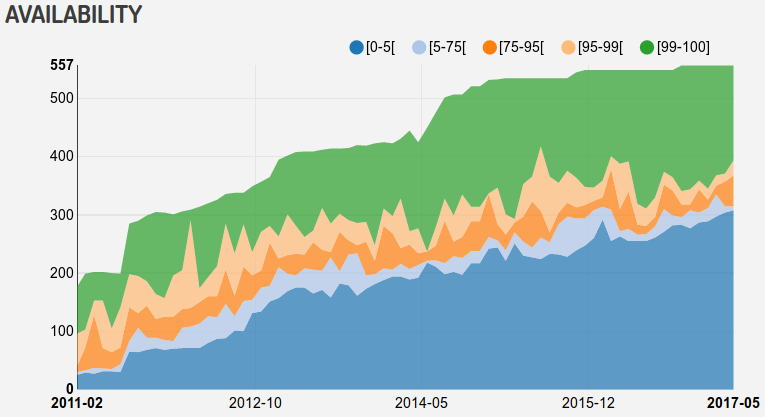
See Chapter 3&5: Scaling Querying/Metadata to the Web
[4/6] Homogeneity Assumption
“Results over few datasets can be generalized to all datasets”
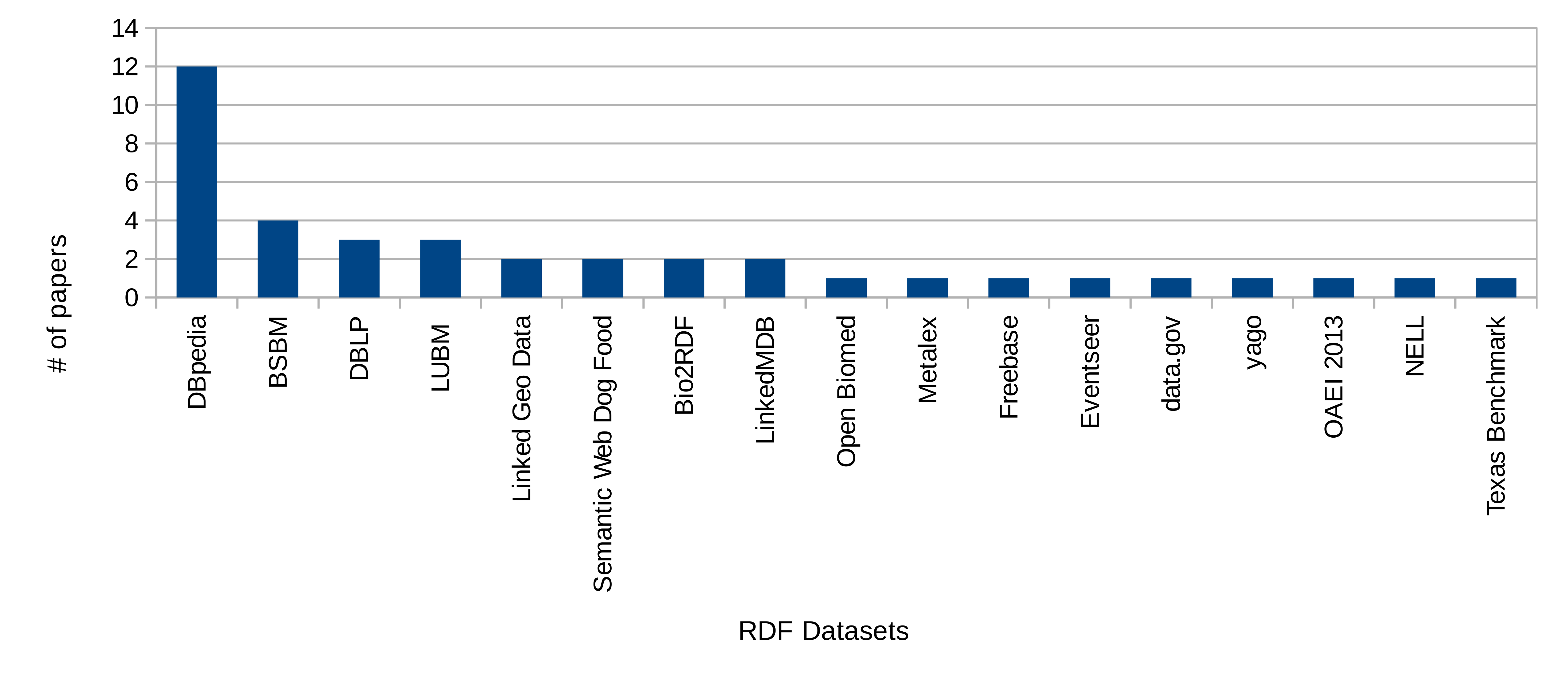
See Chapter 6: Scaling Evaluations to the Web
[5/6] Context-independence Assumption
“Meaning is independent of context”
Things can be (considered) the same in some, but not all contexts.
See Chapter 7: Scaling identity to the Web
[6/6] Declarativeness Assumption
“Meaning is captured by formal semantics”
Graph A
abox:store tbox:sells abox:tent.
abox:tent tbox:costs "¥150,000".
abox:tent rdf:type abox:Product.
Graph B
fy:aHup pe:ko9sap_ fy:jufn12.
fy:jufn12 pe:oao9_ "Ufou".
fy:jufn12 rdf:type fyufnt:tmffqt.
See Chapter 8: Scaling Naming to the Web
Thank you for your attention!
- WWW: wouterbeek.com
- Email: w.g.j.beek@vu.nl